

리눅스 awk 명령어 사용법. (Linux awk command) - 리눅스 파일 텍스트 데이 터 검사, 조작, 출력
1. awk 명령어.
대부분의 리눅스 명령들이, 그 명령의 이름만으로 대략적인 기능이 예상되는 것과 다르게, awk 명령은 이름에 그 기능을 의미하는 단어나 약어가 포함되어 있지 않습니다. awk는 최초에 awk 기능을 디자인한 사람들의 이니셜을 조합하여 만든 이름이기 때문입니다. Aho + Weinberger + Kernighan. (A:Alfred V. Aho, W:Peter J. Weinberger, K:Brian W. Kernighan)

ㅁ x
| [] |
awk는 파일로부터 레코드(record)를 선택하고, 선택된 레코드에 포함된 값을 조작하거나 데이터화하는 것을 목적으로 사용하는 프로그램입니다. 즉, awk 명령의 입력으로 지정된 파일로부터 데이터를 분류한 다음, 분류된 텍스트 데이터를 바탕으로 패턴 매칭 여부를 검사하거나 데이터 조작 및 연산 등의 액션을 수행하고, 그 결과를 출력하는 기능을 수행합니다.
awk에 대한 설명이 잘 이해되시나요? 패턴, 분류, 텍스트, 조작, 연산, 액션. 뭔가 복잡한 작업을 하는 프로그램인 것은 맞는 것 같은데, 구체적으로 어떤 기능을 수행하는지, 어떤 목적을 위해 사용해야 하는지 쉽게 떠오르지 않네요. awk를 어떻게 사용해야 하는지도…
자, 그러면, 구체적인 동작 방식과 사용법을 알아보기에 앞서, awk 명령으로 할 수 있는 일들을 간단히 나열해 보겠습니다.
- 텍스트 파일의 전체 내용 출력.
- 파일의 특정 필드만 출력.
- 특정 필드에 문자열을 추가해서 출력.
- 패턴이 포함된 레코드 출력.
- 특정 필드에 연산 수행 결과 출력.
- 필드 값 비교에 따라 레코드 출력.
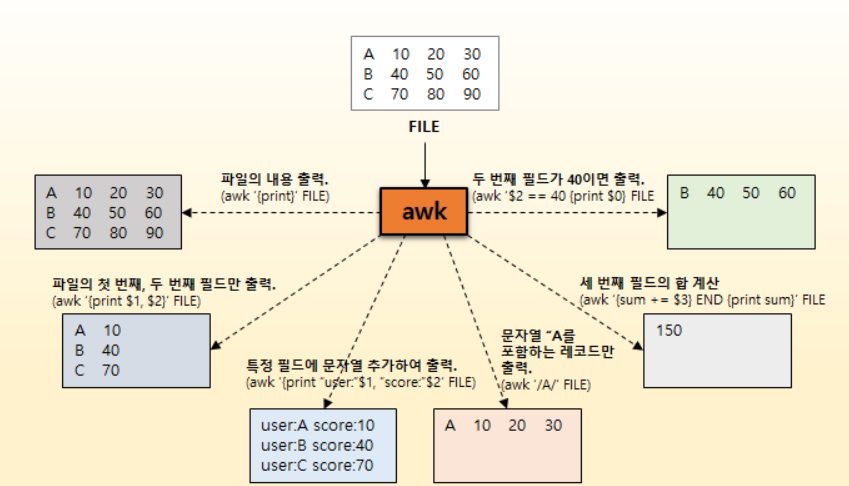
awk로 할 수 있는 작업 중에서, 가장 단순하고 기본적인 몇 개의 예제만 소개해봤는데, awk 명령의 사용 목적이 조금은 이해되시나요? awk 명령에 대한 설명과 소개된 예제를 보면 awk가 어떻게 동작하는지 어느 정도 감을 잡으셨을거라 생각합니다.
awk의 기본 동작 방식 자체는 매우 단순합니다. 입력 데이터로부터 주어진 패턴을 포함하는 라인을 찾기 위해 파일의 내용을 탐색한 다음, 패턴에 일치하는 라인이 발견되면 해당 라인에 대해 지정된 액션을 실행합니다. 그리고 이 과정을 입력 파일의 끝을 만날 때까지 수행합니다. 개념은 단순하죠? 하지만 실질적인 사용법은 꽤 복잡합니다. 이유는 바로, awk가 실행하는 기능(패턴 매칭과 액션 실행) 들이 “프로그래밍 언어”로 작성되기 때문입니다.awk는 “awk programming language“라는 프로그래밍 언어로 작성된 프로그램을 실행합니다. 리눅스에서 쉘 스크립트(Shell Script)로 작성된 파일이 리눅스 쉘(Shell)에 의해 실행되는 것을 떠올리면, awk가 “awk programming language” 문법으로 작성된 코드를 실행한다는 것의 의미가 쉽게 이해되죠.
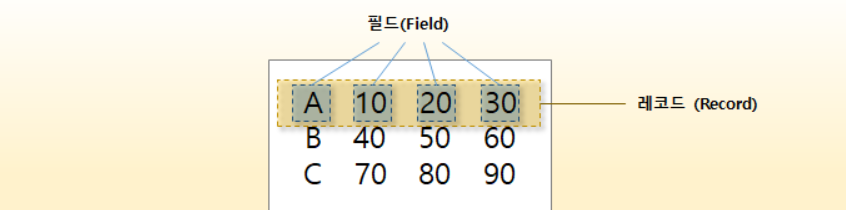
awk는 기본적으로 입력 데이터를 라인(line) 단위의 레코드(Record)로 인식합니다. 그리고 각 레코드에 들어 있는 텍스트는 공백 문자(space, tab)로 구분된 필드(Field)들로 분류되는데요. 이렇게 식별된 레코드 및 필드의 값들은 awk 프로그램에 의해 패턴 매칭 및 다양한 액션의 파라미터로 사용됩니다. (참고로, 레코드 구분 문자(newline)와 필드 구분 문자(space, tab)는 awk 프로그램 옵션으로 변경할 수 있습니다.)
2. awk 명령어 옵션.
awk 명령의 기본 형식과 옵션은 아래와 같습니다.
awk [OPTION...] [awk program] [ARGUMENT...] OPTION -F : 필드 구분 문자 지정. -f : awk program 파일 경로 지정. -v : awk program에서 사용될 특정 variable값 지정. awk program -f 옵션이 사용되지 않은 경우, awk가 실행할 awk program 코드 지정. ARGUMENT 입력 파일 지정 또는 variable 값 지정.
2.1 awk program.
awk 명령의 기본 형식을 보면 알겠지만, awk 명령에는 사용 가능한 옵션이 몇 개 없습니다. 대신, awk 사용자는 옵션의 사용보다는, awk program의 작성에 거의 대부분의 수고를 들이게 되는데요, 앞서 간단히 언급했듯이, awk program은 스크립트 형식의 프로그래밍 언어로 작성되기 때문에, 작성 방법이 매우 다양합니다.
하지만 awk program의 기본 구조는 아래와 같습니다.
pattern { action }그리고 awk 명령에서 awk program은 ‘ ‘(single quotation marks) 안에 작성합니다. 풀어서 써보면 아래 형태가 되겠죠.
awk [OPTION...] 'pattern { action }' [ARGUMENT...]pattern과 action은 모두 생략이 가능한데, pattern을 생략하는 경우는 “모든 레코드”가 적용되고, action을 생략하면 “print”가 적용됩니다. 즉, 아래와 같이 pattern이 생략되는 경우, 매칭 여부를 검사할 문자열 패턴 정보가 없기 때문에 모든 레코드가 선택되고, action을 생략하면, 기본 액션인 print가 실행되는 것입니다.
# pattern 생략.$ awk '{ print }' ./file.txt # file.txt의 모든 레코드 출력.# action 생략.$ awk '/p/' ./file.txt # file.txt에서 p를 포함하는 레코드 출력.pattern과 action에 작성되는 awk program 코드에는 다양한 표현식, 변수, 함수 등이 사용됩니다. 이 중 가장 중요한 변수는 레코드와 필드를 나타내는 변수인데, 하나의 레코드는 $0, 레코드에 포함된 각 필드는 그 순서대로 $1, $2, …, $n 으로 지칭됩니다.
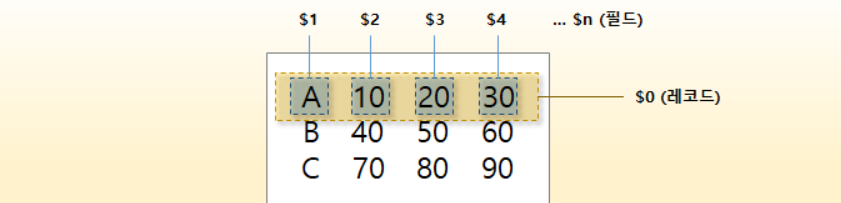
아래 예제는 레코드의 길이가 10 이상인 경우, 세 번째($3), 네 번째($4), 다섯 번째($5) 필드를 출력하는 예제입니다.
$ awk 'length($0) > 10 { print $3, $4, $5} ' ./file.txt그리고 패턴 중에 “BEGIN” 과 “END” 라고 하는 특별한 패턴이 존재하는데요, awk가 BEGIN 패턴을 식별하면 입력 데이터로부터 첫 번째 레코드를 처리하기 전에 “BEGIN”에 지정된 액션을 실행합니다. 그리고 “END” 패턴은 “BEGIN”과 반대로, 모든 레코드를 처리한 다음 “END”에 지정된 액션을 실행합니다.
아래 예제는 “BEGIN”과 “END” 패턴의 사용 예제를 보여줍니다.
$ awk 'BEGIN { print "TITLE : Field value 1,2"} {print $1, $2} END {print "Finished"}' file.txt일단, awk program 을 이해하는데 있어서 가장 기본이 되는 내용들에 대해서만 정리를 했는데요, 이 외에도 awk program에는 많은 수의 표현식과 변수, 함수 등이 제공됩니다. 이 모든 것을 본문에 정리하기는 쉽지 않기 때문에, 본문의 [4. awk program language]에서, 대충 어떤 것들이 있는지만 나열하겠습니다. 좀 더 자세한 내용들에 대해서는 [5. 참고]에 링크된 사이트에서 확인하실 수 있습니다.
3. awk 명령 사용 예제.
앞에서도 설명했듯이, awk 명령은 아래와 같은 형식으로 사용할 수 있습니다.
awk [OPTION...] [pattern {action} ...] [ARGUMENT...]아래 표는 awk 명령 사용 예제를 정리한 것입니다. 각 항목의 링크를 선택하면, 좀 더 자세한 설명과 사용 예제를 확인할 수 있습니다.
| awk 사용 예 | 명령어 옵션 |
|---|---|
| 파일의 전체 내용 출력 | awk '{ print }' [FILE] |
| 필드 값 출력 | awk '{ print $1 }' [FILE] |
| 필드 값에 임의 문자열을 같이 출력 | awk '{print "STR"$1, "STR"$2}' [FILE] |
| 지정된 문자열을 포함하는 레코드만 출력 | awk '/STR/' [FILE] |
| 특정 필드 값 비교를 통해 선택된 레코드만 출력 | awk '$1 == 10 { print $2 }' [FILE] |
| 특정 필드들의 합 구하기 | awk '{sum += $3} END { print sum }' [FILE] |
| 여러 필드들의 합 구하기 | awk '{ for (i=2; i<=NF; i++) total += $i }; END { print "TOTAL : "total }' [FILE] |
| 레코드 단위로 필드 합 및 평균 값 구하기 | awk '{ sum = 0 } {sum += ($3+$4+$5) } { print $0, sum, sum/3 }' [FILE] |
| 필드에 연산을 수행한 결과 출력하기 | awk '{print $1, $2, $3+2, $4, $5}' [FILE] |
| 레코드 또는 필드의 문자열 길이 검사 | awk ' length($0) > 20' [FILE] |
| 파일에 저장된 awk program 실행 | awk -f [AWK FILE] [FILE] |
| 필드 구분 문자 변경하기 | awk -F ':' '{ print $1 }' [FILE] |
| awk 실행 결과 레코드 정렬하기 | awk '{ print $0 }' [FILE] |
| 특정 레코드만 출력하기 | awk 'NR == 2 { print $0; exit }' [FILE] |
| 출력 필드 너비 지정하기 | awk '{ printf "%-3s %-8s %-4s %-4s %-4s\n", $1, $2, $3, $4, $5}' [FILE] |
| 필드 중 최대 값 출력 | awk '{max = 0; for (i=3; i<NF; i++) max = ($i > max) ? $i : max ; print max}' [FILE] |
3.1 파일의 전체 내용 출력.
awk 파일에 “print” 액션만 지정한 경우, 입력으로 지정된 파일의 내용을 출력합니다.
$ awk '{ print }' ./file.txt > file.txt의 전체 파일 내용 출력.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ print }' ./file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 203.2 필드 값 출력.
“print $n” 액션을 통해 n번째 필드 값을 출력할 수 있습니다. 참고로, “$0″은 전체 레코드를 나타내는 변수입니다.
$ awk '{ print $2 }' ./file.txt > 두 번째 필드 값 출력.$ awk '{ print $1,$2 }' ./file.txt > 첫 번째, 두 번째 필드 값 출력.$ awk '{ print $0}' ./file.txt > 레코드 출력.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ print $1, $2}' ./file.txt1 ppotta2 soft3 prog3.3 필드 값에 임의 문자열을 같이 출력.
awk '{print "no:"$1, "user:"$2}' ./file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{print "no:"$1, "user:"$2}' ./file.txtno:1 user:ppottano:2 user:softno:3 user:prog3.4 지정된 문자열을 포함하는 레코드만 출력.
awk의 패턴에 정규 표현식(Regular Expression)을 사용하여 문자열 패턴을 검사할 수 있습니다. 이 때, 정규 표현식은 “/regex/” 형태로 지정할 수 있습니다.
awk '/pp/' ./file.txt # "pp" 가 포함된 레코드만 유효.awk '/[2-3]0/' ./file.txt # 20, 30 이 포함된 레코드만 유효.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '/pp/' ./file.txt1 ppotta 30 40 50$ awk '/[2-3]0/' ./file.txt1 ppotta 30 40 503 prog 90 10 20
3.5 특정 필드 값 비교를 통해 선택된 레코드만 출력.
awk program language의 표현식을 사용하여, 유효한 레코드를 위한 필드 값을 비교할 수 있습니다.
awk '$1 == 2 { print $2 }' ./file.txt # 첫 번째 필드가 2인 레코드의 두 번째 필드 출력.awk '$3 > 70 { print $0 }' ./file.txt # 세 번째 필드가 70보다 큰 레코드 출력.awk '$3 == 30 && $4 ==40 { print $2 }' file.txt # 세 번째 필드가 30이고 네 번째 필드가 40인 레코드의 두 번째 필드 출력.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '$1 == 2 { print $2 }' ./file.txtsoft$ awk '$3 > 70 { print $0 }' ./file.txt3 prog 90 10 20$ awk '$3 == 30 && $4 ==40 { print $2 }' file.txtppotta3.6 지정된 필드의 값을 더한 값 출력. (특정 필드에 대한 합 구하기)
awk program에서 변수의 사용을 통해 특정 필드의 값을 더하고, 더해진 총 합을 출력할 수 있습니다. 이 때, 총합은 모든 레코드 탐색이 끝난 시점인, “END” 패턴의 액션에서 실행합니다.
awk '{sum += $3} END { print sum }' ./file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{sum += $3} END { print "SUM : "sum }' ./file.txtSUM : 1803.7 여러 필드의 값을 더한 값 출력. (여러 필드에 대한 합 구하기)
for 루프를 수행하여 여러 필드의 값을 연산에 포함시킬 수 있습니다. 참고로 아래 예제에서 “NF”는 현재 레코드의 필드 갯수를 뜻하며, “$i”는 변수 i가 매핑된 필드를 뜻합니다. (i=2일 때 $2)
awk '{ for (i=2; i<=NF; i++) total += $i }; END { print "TOTAL : "total }' ./file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ for (i=2; i<=NF; i++) total += $i }; END { print "TOTAL : "total }' ./file.txtTOTAL : 4503.8 레코드 단위로 필드 합 및 평균 값 구하기.
변수 및 액션을 조합하여 레코드 단위로 필드들의 값 및 평균을 계산하여 출력할 수 있습니다.
awk '{ sum = 0 } {sum += ($3+$4+$5) } { print $0, sum, sum/3 }' ./file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ sum = 0 } {sum += ($3+$4+$5) } { print $0, sum, sum/3 }' ./file.txt1 ppotta 30 40 50 120 402 soft 60 70 80 210 703 prog 90 10 20 120 403.9 필드에 연산을 수행한 결과 출력하기.
awk program 표현식을 사용하여, 필드에 연산을 수행한 결과를 출력할 수 있습니다.
awk '{print $1, $2, $3+2, $4, $5}' ./file.txt # 세 번째 필드에 2를 더한 값을 출력.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{print $1, $2, $3+2, $4, $5}' ./file.txt1 ppotta 32 40 502 soft 62 70 803 prog 92 10 203.10 레코드 또는 필드의 문자열 길이 검사.
length() 함수를 사용해 레코드 또는 필드의 문자열 길이를 확인할 수 있습니다.
awk ' length($0) > 20' ./file.txt # 레코드의 길이가 20보다 큰 경우.awk ' length($2) > 4 { print $0 } ' ./file.txt # 두 번째 필드의 길이가 4보다 큰 레코드 출력.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk ' length($2) > 4 { print $0 } ' ./file.txt1 ppotta 30 40 503.11 파일에 저장된 awk program 실행.
awk 실행 시, “-f” 옵션을 사용하여 파일로부터 awk program을 실행할 수 있습니다.
awk -f awkp.script ./file.txt # awkp.script에 저장된 awk program 실행$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ cat awkp.script{ for (i=2; i<=NF; i++) total += $i}END { print "TOTAL : "total}$ awk -f awkp.script ./file.txtTOTAL : 4503.12 필드 구분 문자 변경하기.
기본적으로 레코드의 필드를 구분하는 문자는 space 입니다. 이를 “-F” 사용하여 변경할 수 있습니다.
awk -F ':' '{ print $1 }' ./file.txt # 필드 구분 문자를 : 로 변경.awk -F ',' '{ print $1 }' ./file.txt # 필드 구분 문자를 , 로 변경.$ cat file2.txt1, ppotta, 30, 40, 502, soft, 60, 70, 803, prog, 90, 10, 20$ awk -F ',' '{ print $1 }' ./file2.txt1233.13 awk 실행 결과 레코드 정렬하기.
awk 명령과 sort 명령을 조합하여, awk 실행 결과로 출력되는 레코드를 정렬할 수 있습니다.
awk '{ print $0 }' file.txt | sort # 출력 레코드를 오름차순으로 정렬.awk '{ print $0 }' file.txt | sort -r # 출력 레코드를 역순으로 정렬.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ print $0 }' file.txt | sort -r3 prog 90 10 202 soft 60 70 801 ppotta 30 40 503.14 특정 레코드만 출력하기.
exit 키워드를 사용하여, 조건에 따라 awk 실행을 중지시킬 수 있습니다.
awk '{ print $0; exit }' file.txt # 첫 번째 레코드만 출력하고 실행 중지.awk 'NR == 2 { print $0; exit }' file.txt # 두 번째 레코드만 출력하고 실행 중지.$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk 'NR == 2 { print $0; exit }' file.txt2 soft 60 70 803.15 출력 필드 너비 지정하기.
printf 함수를 사용하여 필드 값 출력 포맷을 지정할 수 있습니다. printf 함수에 사용하는 출력 포맷은 C 언어와 동일합니다.
awk '{ printf "%-3s %-8s %-4s %-4s %-4s\n", $1, $2, $3, $4, $5}' file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{ printf "%-3s %-8s %-4s %-4s %-4s\n", $1, $2, $3, $4, $5}' file.txt1 ppotta 30 40 50 2 soft 60 70 80 3 prog 90 10 203.16 필드 중 최대 값 출력.
아래와 같은 코드를 통해 레코드 내 필드의 최대 값을 구하여 출력할 수 있습니다.
awk '{max = 0; for (i=3; i<NF; i++) max = ($i > max) ? $i : max ; print max}' ./file.txt$ cat file.txt1 ppotta 30 40 502 soft 60 70 803 prog 90 10 20$ awk '{max = 0; for (i=3; i<NF; i++) max = ($i > max) ? $i : max ; print max}' ./file.txt4070904. awk program language
awk program 이 프로그래밍 언어로 작성되는 만큼 다양한 요소들을 사용하여 프로그래밍됩니다.
먼저 awk 표현식은 C 프로그래밍 언어 표현식과 유사한 형태로 제공됩니다.
(E), $n, ++E, --E, E++, E--, E^E, !E, +E, -E, E*E, E/E, E%E, E+E, E-E, E E, E<E, E<=E, E!=E, E==E, E>E, E>=E, E~E, E!-E, E in array, (n) in array, E&&E, E||E, E1?E2:E3 V^=E, V%=E, V*=E, V/=E, V+=E, V-=E, V=Eawk program에는 아래와 같은 키워드가 제공됩니다.
BEGIN delete END function in printf break do exit getline next return continue else for if print whileawk program 에서는 새로운 변수를 선언하고 값을 할당하거나 참조할 수 있습니다. 그리고 아래와 같이 특수 목적으로 미리 정의된 변수들을 사용할 수 있습니다.
ARGC : ARGV 배열 요소의 갯수. ARGV : command line argument에 대한 배열. CONVFMT : 문자열을 숫자로 변경할 때 사용할 형식. (ex, "%.6g") ENVIRON : 환경변수에 대한 배열. FILENAME : 경로를 포함한 입력 파일 이름. FNR : 현재 파일에서 현재 레코드의 순서 값. FS : 필드 구분 문자. (기본 값 = space) NF : 현재 레코드에 있는 필드의 갯수. NR : 입력 시작 점에서 현재 레코드의 순서 값. OFMT : 문자열을 출력할 때 사용할 형식. OFS : 결과 출력 시 필드 구분 문자. (기본 값 = space) ORS : 결과 출력 시 레코드 구분 문자. (기본 값 = newline) RLENGTH : match 함수에 의해 매칭된 문자열의 길이. RS : 레코드 구분 문자. (기본 값 = newline) RSTART : match 함수에 의해 매칭된 문자열의 시작 위치.awk program 에서 사용할 수 있는 함수들에는 아래와 같은 것들이 있습니다.
Arithmetic Functions : atan2(y,x), cos(x), sin(x), exp(x), log(x), sqrt(x), int(x), rand(), srand([expr])String Functions : gsub(ere, repl[, in]), index(s, t), length[([s])], match(s, ere), split(s, a[, fs ]), sprintf(fmt, expr, expr, ...), sub(ere, repl[, in ]), substr(s, m[, n ]), tolower(s), toupper(s)Input/Output and General Functions : close(expression), getline getline var system(expression)5. 참고.
- GNU Awk User’s Guide.
- [GNU Awk User’s Guide.] 내용을 참고하세요.
- Man7 Linux Manual Page – awk
- [Man7. man. awk] 내용을 참고하세요.
.END.
[출처] 리눅스 awk 명령어 사용법. (Linux awk command) – 리눅스 파일 텍스트 데이터 검사, 조작, 출력.|작성자 하나자바
문제가 될 시 삭제하겠습니다.



