

마이크로소프트가 M5 맥북을 경계해야 하는 이유
애플의 맥 미니는 로컬 AI 실행 장치로 개발자 사이에서 빠르게 인기를 얻고 있다. 애플이 새로 공개한 맥북 프로는 애플 M5 프로와 애플 M5 맥스 칩을 탑재하면서 개발자를 더욱 끌어들일 가능성이 제기된다.
애플은 이번 주 새로운 맥북 프로를 공개했다. 해당 제품은 3나노미터 CPU 다이 2개를 결합하고 두 다이 사이를 연결하는 인터커넥트 구조를 적용했다. Macworld 기자 제이슨 크로스는 듀얼 다이 설계가 완전히 새로운 방식은 아니라고 설명했다. AMD의 라이젠 9 5950X와 라이젠 9 7950X3D 같은 프로세서도 칩렛 2개를 인피니티 패브릭 인터커넥트로 연결하는 구조를 사용한다.
애플 M5 칩에서 새롭게 주목받는 요소는 슈퍼 코어와 성능 코어 도입이다. 일부 구조는 슈퍼 코어라는 명칭 변경에 가깝다는 분석도 나온다. 반면 새로운 성능 코어는 아직 세부 구조가 충분히 공개되지 않았다. 그러나 핵심은 20~40코어 GPU와 신경망 가속기가 결합된 구조이며, 최대 128GB 통합 메모리를 지원한다는 점이다. 이런 구조는 일반적인 윈도우 PC와 차별화된 구조이며 애플 사용자에게 여러 장점을 제공한다.
현재 애플 최신 칩의 세부 구조는 아직 완전히 공개되지 않았다. 8월 열리는 핫 칩스 반도체 콘퍼런스에서 더 깊은 분석이 공개될 가능성이 있다. 하지만 공개된 핵심 사양만으로도 애플 설계 방향을 이해하기에는 충분하다.
메모리 구조가 핵심…M5 맥스 맥북의 강점
가장 인상적인 요소는 메모리 구성이다. 애플 M5 맥스 칩은 기본 48GB 통합 메모리를 제공하며 최대 128GB까지 확장 가능하다. 애플 제품 구성 페이지는 다소 복잡하지만 모든 16인치 맥북 프로 모델이 해당 용량으로 구성 가능한 것으로 보인다. 해당 구성의 가격은 4,399달러 수준이다. 중요한 점은 통합 메모리 구조라는 점이다.
오랫동안 AMD와 인텔 기반 윈도우 노트북은 전용 비디오 메모리 구조를 사용했다. 인텔 노트북은 시스템 메모리의 절반을 그래픽 메모리로 사용하는 구조였고 라이젠 노트북도 일정 용량의 VRAM을 별도로 할당했다. AMD가 라이젠 AI 맥스 프로세서를 발표했을 때 아드레날린 소프트웨어를 업데이트해 VRAM 용량을 동적으로 조정할 수 있도록 했다. 지난해 8월 인텔은 공유 GPU 메모리 오버라이드 기능을 발표해 비슷한 기능을 제공했다. 퀄컴의 Arm 기반 프로세서는 애플 M5 프로와 M5 맥스와 구조적으로 가장 유사하지만 동일한 기능을 제공하지 않는다.
Screenshot
Apple
애플 M5 칩은 MLX라는 오픈소스 배열 프레임워크를 사용한다. MLX는 로컬 AI 처리를 한 단계 끌어올린 기술로 평가된다. MLX는 사용자가 메모리 할당량을 직접 계산할 필요가 없다. 시스템이 자동으로 선택하는 구조도 아니다. 대신 신경망 학습과 추론, 텍스트 생성, 이미지 생성을 지원하며 CPU와 GPU 중 어느 곳에서든 메모리 이동 없이 실행할 수 있도록 설계됐다. 복잡한 설정 없이 동작하는 구조라는 설명이다.
AI 모델은 PC에서 가장 빠른 메모리를 적극적으로 사용한다. 일반적으로 GPU의 비디오 메모리가 해당 역할을 한다. 가장 강력한 AI 모델은 대부분 복잡한 구조를 가진다. 모델 성능은 보통 파라미터 수로 평가되며 규모가 클수록 성능이 높다. 그러나 대형 모델은 그만큼 많은 메모리 공간을 요구한다. 예를 들어 윈도우 운영체제가 2GB 메모리 환경에서 정상적으로 동작하기 어려운 것과 같은 원리다. 어도비 포토샵 역시 상당한 메모리 용량을 요구한다.
정리하면 M5 맥북 프로는 최대 128GB 메모리를 제공하며 대부분 용량을 GPU, 즉 AI 처리 엔진이 활용할 수 있다. 해당 용량은 현재 가장 강력한 PC 그래픽 카드인 엔비디아 RTX 5090의 32GB 비디오 메모리보다 훨씬 많다. 4,399달러 가격이 부담스럽다면 3,099달러 맥북 프로 모델도 기본 48GB 통합 메모리를 제공한다.
이 구조 덕분에 맥북은 일반적으로 클라우드에서 실행해야 하는 대형 AI 모델도 로컬 장치에서 실행할 수 있다. 지연 시간이 없고 구독 비용이 필요 없으며 데이터가 외부 서버로 전송되지 않는다는 장점이 있다. 애플이 공개한 자료에 따르면 여러 AI 모델이 맥북에서 안정적으로 실행 가능하다. Qwen3 모델의 메모리 할당을 두 배로 늘리면 700억 파라미터 모델 실행도 가능하다는 분석이다. 또한 모델 양자화를 통해 정밀도를 낮춰 모델 크기를 줄이는 코드도 공개했다.
Foundry
애플 설계는 성능 구조에서도 차별성을 보인다. AMD, 인텔, 퀄컴 프로세서는 통합 GPU를 포함한다. 반면, 애플은 각 GPU 코어 안에 신경망 처리 장치를 포함한 신경망 가속기를 배치한다. 이 신경 가속기는 머신러닝 계산에 필요한 행렬 연산을 수행한다. 또한 16코어 신경 엔진이라는 별도의 신경망 처리 장치도 존재한다. 다만 GPU, 신경망 가속기, 신경 엔진 사이의 상호 작용 구조는 아직 명확히 공개되지 않았다.
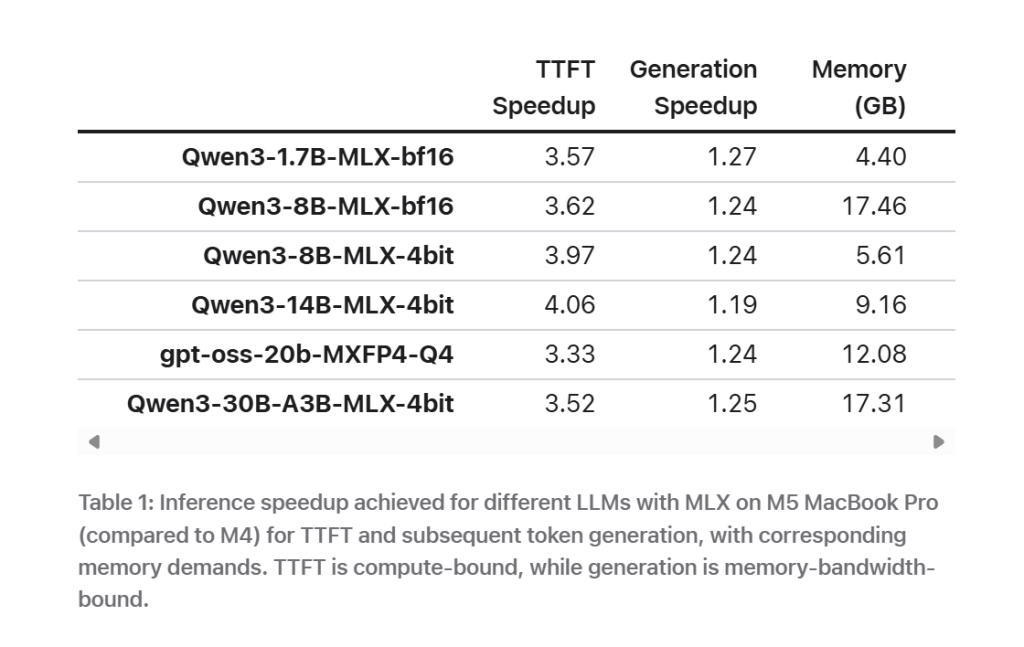
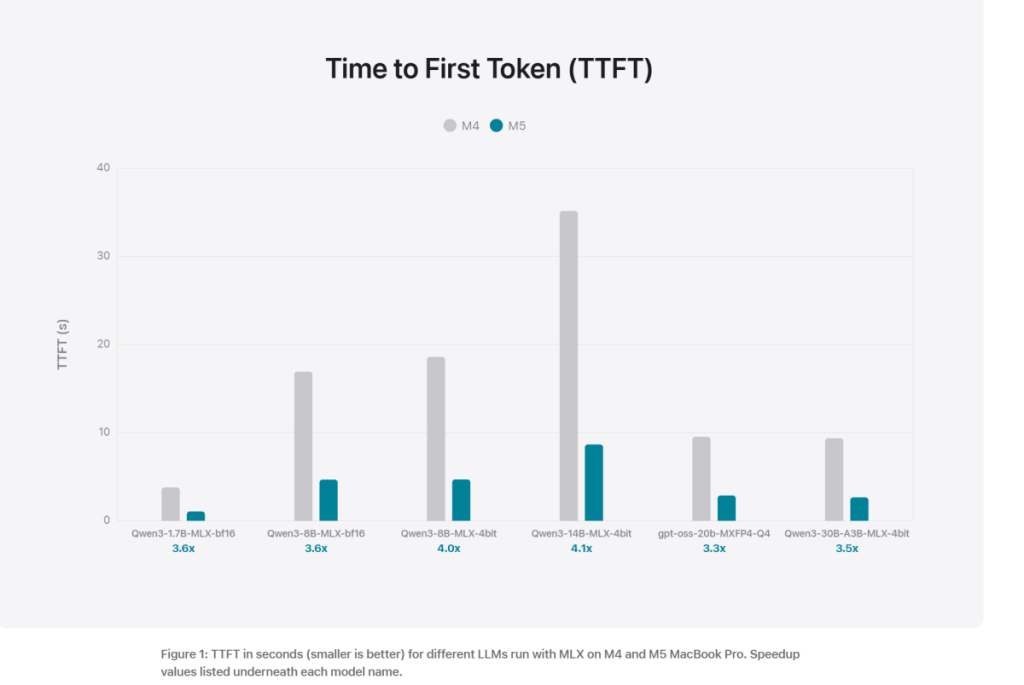
그럼에도 애플은 첫 토큰 생성 시간이 크게 개선됐다고 설명한다. 대규모 언어 모델이 사용자 입력에 응답하기까지 걸리는 시간이다. 해당 수치는 위 표와 아래 그래프에서 확인할 수 있다.
Foundry
개인적인 대규모 언어 모델 사용 경험에서는 응답 속도가 가장 중요한 요소는 아니다. 빠른 응답은 편리하지만 문자 생성이 점진적으로 출력되는 방식은 오히려 읽기 어려울 때도 있다. 결국 중요한 요소는 응답의 정교함과 품질이다.
윈도우 생태계가 따라갈 수 있을까
공정하게 말하면 마이크로소프트도 유사한 개념을 준비하고 있다. 윈도우 ML은 PC에서 가장 강력한 반도체 자원을 활용해 로컬 AI 애플리케이션을 실행하는 기술이다. 특정 신경망 처리 장치가 없어도 시스템에서 가장 강력한 연산 장치를 활용하는 방식이다. 어느 접근 방식이 더 우수한지는 실제 테스트가 필요하다.
AMD의 라이젠 AI 맥스+는 강력한 AI 프로세서로 평가된다. 라이젠 AI 맥스+ 395는 80MB 캐시를 활용해 AI 처리 성능을 높인다. AMD는 프로세서에 대용량 캐시를 추가하는 전략으로 이미 여러 차례 성능 향상을 이끌어낸 경험이 있다.
한편 애플 스토어 직원이 맥 미니 판매 증가에 놀랐다는 일화도 전해진다. 맥 미니는 대규모 언어 모델이나 에이전트형 AI을 로컬 환경에서 실행하려는 개발자에게 유용한 장치로 평가된다. 전력 소비가 적고 AI 토큰 구독 비용도 필요 없기 때문이다. 새 맥북 프로는 이런 기능에 디스플레이를 추가한 형태로 볼 수 있다.







